The other day, I found myself having one of those nice coffee shop chats that just don't happen often enough. I was in Waterloo, having walked the four km that separate the University of Waterloo Research and Technology park from downtown (are all tech workers meant to have cars?). After that walk, a coffee shop seemed like a good place to set down for a while and get some work done. I asked the man at the next table to watch my computer for a moment. This led, when I got back to my table, to a discussion about computers, the danger of losing them and, more importantly, the danger of losing the data stored on them, which is often so much more valuable than the machine.
Data loss is the main theme here. The gentleman at the next table explained that for his work, he relies heavily on reference management software, being engaged in research. That reliance, among research types, is unremarkable. Reference management software is a pretty common thing to use. I'll somewhat bashfully say that in my own research-y work, I don't use it. I just build reference lists in OpenOffice. It's not a particularly tidy or clever way of doing things, and it probably slows me down, given that, when I need to find something I've cited before, I find myself combing through piles of old files, looking for the right entry.
Given that we were discussing F/LOSS (I take every opportunity to show just how un-scary Linux and other F/LOSS are), the question of F/LOSS reference management software came up. Not being a user of such software, I didn't have any good suggestions about an alternative to the dominant applications like Refworks and Endnote. However, in an example of proper esprit d'escalier, I now have such a suggestion.
Yesterday, in an attempt to avoid writing an abstract while still pretending to get things done, I spent some time fiddling around with JabRef. And it's quite nice. It imports from a variety of sources (JStor, Endnote and annotated PDFs, to name a few) and exports a variety of suitable formats (including BibTeXML, HTML, plain text, RTF and a few different flavours of OpenOffice formatting). And, the quite nice thing, it's painless and organized. Adding a source (with any number of different fields) is simple. Searching those sources is simple, making subsets of the database is simple. I'll be the first to admit that I have no idea how it stacks up against the competition, but on its own merits, I quite like it. In fact, I think I'll be fiddling with it quite a bit in the next few months, as I try to keep my giant reference list better organized.
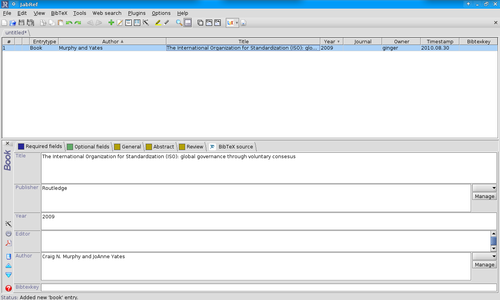
JabRef v. my current non-system system. It's tidy, it's centralized and it works beautifully, not to mention easily. Score one for JabRef. Added bonus: no install needed. It can be run just by clicking the "Run JabRef" button on the JabRef website.
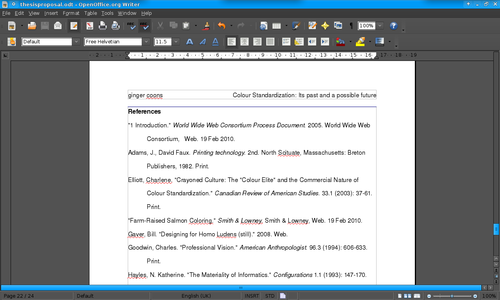
Data loss is the main theme here. The gentleman at the next table explained that for his work, he relies heavily on reference management software, being engaged in research. That reliance, among research types, is unremarkable. Reference management software is a pretty common thing to use. I'll somewhat bashfully say that in my own research-y work, I don't use it. I just build reference lists in OpenOffice. It's not a particularly tidy or clever way of doing things, and it probably slows me down, given that, when I need to find something I've cited before, I find myself combing through piles of old files, looking for the right entry.
Given that we were discussing F/LOSS (I take every opportunity to show just how un-scary Linux and other F/LOSS are), the question of F/LOSS reference management software came up. Not being a user of such software, I didn't have any good suggestions about an alternative to the dominant applications like Refworks and Endnote. However, in an example of proper esprit d'escalier, I now have such a suggestion.
Yesterday, in an attempt to avoid writing an abstract while still pretending to get things done, I spent some time fiddling around with JabRef. And it's quite nice. It imports from a variety of sources (JStor, Endnote and annotated PDFs, to name a few) and exports a variety of suitable formats (including BibTeXML, HTML, plain text, RTF and a few different flavours of OpenOffice formatting). And, the quite nice thing, it's painless and organized. Adding a source (with any number of different fields) is simple. Searching those sources is simple, making subsets of the database is simple. I'll be the first to admit that I have no idea how it stacks up against the competition, but on its own merits, I quite like it. In fact, I think I'll be fiddling with it quite a bit in the next few months, as I try to keep my giant reference list better organized.
JabRef v. my current non-system system. It's tidy, it's centralized and it works beautifully, not to mention easily. Score one for JabRef. Added bonus: no install needed. It can be run just by clicking the "Run JabRef" button on the JabRef website.
Having found JabRef and enjoying my explorations with it, I'm pleased to have yet another nice little bit of software in my arsenal, for the next time someone asks if there's an alternative to their favourite proprietary program. Once again (as previously posited in Banff), chatting with strangers proves to be both useful and illuminating.
Leave a comment